Table of Contents
VLFeat implements a fast dense version of
SIFT, called
vl_dsift. The function is roughly equivalent to running
SIFT on a dense gird of locations at a fixed scale and
orientation. This type of feature descriptors is often uses for object
categorization.
Dense SIFT as a faster SIFT
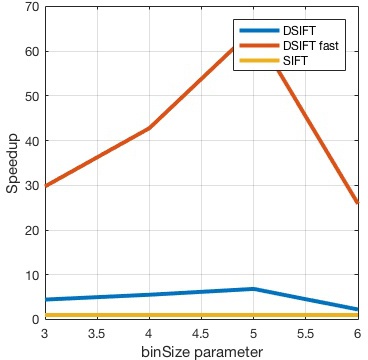
The main advantage of using vl_dsift
over vl_sift is speed. To see this, load a test image
I = vl_impattern('roofs1') ;
I = single(vl_imdown(rgb2gray(I))) ;
To check the equivalence of vl_disft
and vl_sift it is necessary to understand in detail how
the parameters of the two descriptors are related.
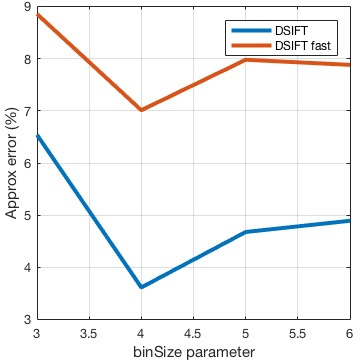
Bin size vs keypoint scale. DSIFT specifies the descriptor size by a single parameter,
size, which controls the size of a SIFT spatial bin in pixels. In the standard SIFT descriptor, the bin size is related to the SIFT keypoint scale by a multiplier, denotedmagnif below, which defaults to3. As a consequence, a DSIFT descriptor with bin size equal to 5 corresponds to a SIFT keypoint of scale 5/3=1.66.Smoothing. The SIFT descriptor smoothes the image according to the scale of the keypoints (Gaussian scale space). By default, the smoothing is equivalent to a convolution by a Gaussian of variance
s^2 - .25, wheres is the scale of the keypoint and.25 is a nominal adjustment that accounts for the smoothing induced by the camera CCD.
Thus the following code produces equivalent descriptors using either DSIFT or SIFT:
binSize = 8 ; magnif = 3 ; Is = vl_imsmooth(I, sqrt((binSize/magnif)^2 - .25)) ; [f, d] = vl_dsift(Is, 'size', binSize) ; f(3,:) = binSize/magnif ; f(4,:) = 0 ; [f_, d_] = vl_sift(I, 'frames', f) ;
The difference, of course, is that DSIFT is much faster.
PHOW descriptors
The PHOW features [1] are a variant of dense
SIFT descriptors, extracted at multiple scales. A color version, named
PHOW-color, extracts descriptors on the three HSV image channels and
stacks them up. A combination of vl_dsift
and vl_imsmooth can be used to easily and efficiently
compute such features.
VLFeat includes a simple wrapper, vl_phow, that does
exactly this:
im = vl_impattern('roofs1') ;
[frames, descrs]=vl_phow(im2single(im)) ;
Note that this typically generate a very large number of features. In this example, there are 162,574 features.
References
- [1] A. Bosch, A. Zisserman, and X. Munoz. Image classifcation using random forests and ferns. In Proc. ICCV, 2007.